Изкуствени невронни мрежи (ИНМ)
1. Теория на ИНМ с обратно разпространение на грешката.
Изкуствените невронни мрежи са математически
обекти, които изобразяват едно векторно пространство в друго. Тяхната
архитектура е вдъхновена от паралелната обработка на
информация, която се извършва в човешкия мозък. Те са изградени от единици,
наречени неврони, които обработват входящите сигнали и препращат изхода към
други неврони. Съществуват няколко класа невронни мрежи [1-3],
които се различават по схемата на свързване на невроните, по стойностите на
обработваните сигнали и по вида на преобразуващата
функция.
Засега, най-много приложения в
химията намират невронните мрежи, разпространяващи напред сигналите (forward feed) и извършващи корекция на грешките в обратна
посока (back propagation of errors). Невронните мрежи с обратно
разпространение на грешките са изградени от няколко слоя неврони: входен слой,
няколко скрити слоя и един изходен слой – фигура 1. Всеки
неврон получава сигнали от всички неврони на предхождащия слой и изпраща
изходни (обработени) сигнали към всички неврони на следващия слой. Полученият
(чист) сигнал на един неврон, Netj, е сума от произведенията на
коефициентите на мрежата (силата на връзките,
Wj,k)
и изходните сигнали от предхождащия слой, Outk.
Netj = Wj,k*Outk (1)
Netj се
обработва по-нататък от т.н. изглаждаща (squashing) функция (фигура 1, в ляво), за да се получи изходен
сигнал в интервала 0.0 - 1.0.
Когато невронните мрежи се
използват за обработка на спектри (или произволни криви), входните вектори се
формират от спектралната крива или набор от други спектрални признаци, които се
представят като един многомерен вектор. Изходните
вектори се получават, например, от информацията за структурата на съответните химични
съединения; те също са вектори, но с координати нула или единица, показващи
наличието (1.0) или отсъствието (0.0) на даден
структурен фрагмент. Съответно броят на входните/изходните неврони съвпада с
размерността на входните/изходните вектори. За да се получат
спектро-структурните корелации между спектрите и съответните структурни
дескриптори е необходимо невронната мрежа да бъде обучена с подходяща по обем и
представителност извадка от спектри на съединения с известна структура,
наречена обучаваща извадка (learning set). Входните вектори
(спектрите) се пропускат последователно през мрежата, като получените изходни
вектори се сравняват с целевите изходни вектори, отразяващи структурата на
съединенията.
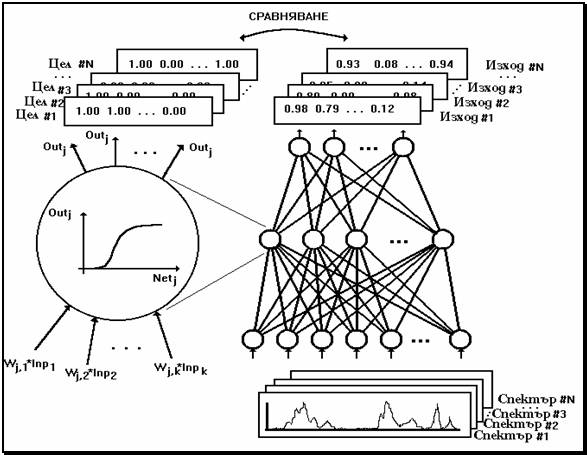
Фигура 1. Схема на изкуствена
невронна мрежа с право разпространение на сигналите и
обратно разпространение на грешките.
Получените грешки се
"разпространяват" обратно като биват променяни стойностите на
коефициентите на мрежата [1, 3].
Wi,j(new) = Wi,j(old) + *Wi,j(calc) + *Wi,j(old) (2)
Wi,j (calc) включва разпространението на грешката и се
изчислява чрез параметри, специфични за всеки слой от неврони. Параметърът се нарича скорост на обучение (learning rate) и
определя големината на градиента, т.е. влияе върху
сходимостта на оптимизационната процедура. Параметърът се нарича моментен коефициент (momentum factor) и заедно с Wi,j(old), която е грешката от предходното обучение,
спомага за преодоляване на локалните минимуми, запазвайки една стабилна посока
на преход към минимума – пълното съвпадение на
реалните и целевите изходи. Именно стойностите на коефициентите Wi,j съдържат спектро-структурните корелации, при което знанията се пазят подобно на тези в човешкия
мозък – разпределено.
Еднократно преминаване на всички входни вектори през мрежата и съответните корекции се нарича цикъл, епоха или сесия (epoch, session) и обикновено няколко стотин или хиляди цикъла са необходими за пълното обучение на мрежата. След обучението на мрежата, тя е способна да обработва спектри на съединения, невключени в обучаващата извадка, т.е. изкуствените невронни мрежи могат да обобщават постигнатите знания върху непознати обекти и се характеризират с предсказваща способност (prediction ability). Тази характеристика на невронните мрежи ги прави привлекателен обект за използване в компютърните системи за обработка на спектрална информация.
В следващите статии ще бъде
разгледана подробно архитектурата на тези ИНМ и ще бъде даден примерен
програмен код на Делфи 2.
- D.E.
Rumelhart (Ed.); Parallel
Distributed Processing. MIT Press,
- T.
Kohonen; Self-Organization and
Associative Memory. Springer Verlag,
- J. Zupan, J. Gasteiger; Neural Networks for Chemist: An Introduction. VCH Publishers,
Автор: Пламен Пенчев
[това е статия от брой 7 на списание “Коснос” http://www.kosnos.com]