
Фигура 1. Таблица на свързаност
и 2D диаграма, представящи структурата на изо-бутана.
1. Проблеми на химичната информатика. Приложенията на химичната информатика се характеризират с голямо разнообразие от методи. Основна характеристика за всеки един метод е химичната структура – начина, по който тя се представя, подходите за съхранение и обработка на структурната информация и установяването на връзки между структурите и друга химична информация. Понастоящем, съществува голям интерес към развитието на алгоритми и системи с бази данни за 3D представяния на молекулите и техните конформационно зависими свойства. Целева група на химичната информатика са над 50 милиона органични съединения.
Още преди десетилетия се стига до извода, че огромното количество информация, събирана и натрупвана от химиците, може да бъде ефективно използвана от научната общност в електронна форма. Това ново направление, което се занимава със съхранението, управлението и развитието на химичната информация, се появява без подходящо име. В повечето случаи учените, използващи това поле, казвали, че работят върху „Химичната информация” [1]. Тъй като термина „Химична информация” не уточнява дали информацията се обработва в библиотеки или чрез компютърни методи, някои учени определяли областта на работата си като „Компютърна химия”, за да подчертаят важността, която отдават при използването на компютъра за развитието на химичната информация. Друго понятие е „Изчислителната химия”, която се възприема от други химици като понятие, отнасящо се само до теоретичните квантово-механични изчисления. През 1975 г. списанието „Списание за химична документация” (Journal of Chemical Documentation) променя името си на „Списание за химична информация и компютърни науки” (Journal of Chemical Information and Computer Sciences). През 1973 г. се провежда лятна конференция на NATO Advanced Study Institute, където за първи път се обединяват широк кръг от учени, които идват от различни области на химията, като всички от тях развиват компютърните методи, за да разберат и да боравят с химическата информация. Лятната школа била под наслов: "Компютърът относно представяне и управление на химичната информация". Групите, присъстващи на тази конференция, работили по изграждането на бази данни с химически структури и разработването на софтуер за молекулно моделиране, планиране на органичен синтез, за анализ на спектрална информация, както и в областта на Химиметрията [2]. В по-общ план приложенията на математиката и информатиката в химията са толкова всеобхватни, че всички тези направления не могат да бъдат покрити от една конференция.
Някои от основните направления, с които химичната информатика се занимава, са:
• Предстaвяне на химични съединения и химични
реакции;
• Обработка на химични данни;
• Поддръжка на химични бази данни;
• Търсене на химични структури;
• Изисляване на молекулни дескриптори;
• Моделиране/предсказване на физични и
химични свойства;
• Разкриване на структурите на неизвестни
химични
съединения;
• Моделиране на химичен синтез;
• Разработване на специализиран химически
софтуер;
• Информационно обслужване на различните
клонове в химията.
2. Представяне на структурна информация. Химичната информатика използва много от методите на Химиметрията, но най-отличителната черта на Химичната информатика е, че компютърните подходи по някакъв начин винаги са свързани със структурата на химичните съединения. Структурното представяне е ключов елемент за Химичната информатика. През последните три десетилетия били установени няколко похвата за структурно представяне, като: таблиците на свързаност, линейните нотации, 2D и 3D представяния, структурни дескриптори и др. Тъй като структурното представяне е много важно за ефективността на методите на химичната информатика, в следващите секции е направен литературен преглед на основните методи за структурно представяне.
2.1. Таблица на свързаност. Няма да бъде преувеличено, ако кажем, че основния подход за структурно представяне е таблицата на свързаност [3]. Таблицата на свързаност се използва за изпълнението на всички основни задачи на химичния софтуер: при обработка и съхранение на структурна информация, трансфер, визуализация, конвертиране на едно в друго структурно представяне, пресмятане на молекулните дескриптори, моделиране на молекулни свойства. Таблицата на свързаност oписва напълно топологичната информация от молекулния граф и също така е доминиращата форма за представяне на структурна информация в софтуерните системи. Тя е основното топологично представяне на структурна информация, базирана върху дадено номериране на атомите. Въпреки че през последните десетилетия бяха разработени софтуерни пакети за автоматично преобразуване от номенклатурата на IUPAC в таблица на свързаност и обратно, номенклатурите се използват като допълнителна информация с вторична цел в химичните бази данни. Структурните регистрационни номера, въведени от различни фирми за техните собствени химични бази от данни (например CAS-RN) предоставят полезен ключ за интернет търсене, но те нямат директна кореспонденция със структурната информация. За повечето файлови формати таблицата на свързаност е като ядро, около което са закрепени допълнителни данни: атомни атрибути, атрибути на връзките, молекулни атрибути и др. Структурните данни също се съобщават на химика, с помощта на различни подходи за графично визуализиране.
Фигура 1. Таблица на свързаност
и 2D диаграма, представящи структурата на изо-бутана.
2.2. Линейни нотации. Линейните
нотации представляват подходи, чрез които информацията за свързаността
е представена линейно, като символен низ. Тези символно-низови представяния,
в повечето случаи, се подчиняват на следните условия: компактност, пълно
представяне на свързаността, ефективна обработка с компютър. Линейните
нотации са много полезни, защото могат да бъдат третирани ефективно, както
директно от човек, така и чрез софтуер. От 1980 година насам множество
линейни нотации са били развити. Някои от настоящите най-популярни нотации
са: SMILES [4,5], SLN (Sybil Line Notation) [6], ROSDAL [7] (Вж. фиг. 1.2).
Тези линейни нотации представят същата информация от таблиците на свързаност,
но съхранена по различен начин – като низ. Употребата на линейните нотации
изисква софтуерни парсъри (parser – синтактичен анализатор), които практически
генерират таблица на свързаност за дадения низ на линейната нотация. Линейните
нотации са полезни за съхранение в база данни, както и за пряко въвеждане
на химична информация от потребителя. Важно е да се отчете, че всяка линейна
нотация е предназначена за различен тип задачи, съответстващи на различни
типове химични обекти: съединения, заявки за търсене, реакции, множество
от съединения, комбинаторни библиотеки, Маркуш структури и т.н. Например
SMILES нотацията се използва за описание на структурата на химично съединение,
докато SMARTS [8] (език, произхождащ от SMILES) се използва за описание
на заявки за субструктурно търсене. Въпреки, че двете може да изглеждат
идентично в много случаи, първата описва валидна молекула, докато втората
нотация описва фрагмент, който се търси в база данни с целеви молекули.
Друг пример: SLN е по-универсална нотация, която може да се използва за
описание на структури, заявки за търсене, комбинаторни библиотеки,
Markush структури [9]. Систематичните и тривиални номенклатури в по-общ
смисъл могат да се разглеждат като частен случай на линейните нотации.
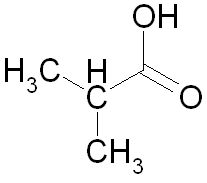 |
... | Линейни нотации
Smiles: CC(C)C(=O)OH
|
Фигура 2. Линейни нотации, описващи структурата на изобутановата киселина.
3. Субструктурно търсене. Търсенето на химични структури е основна задача в Химичната информатика. Има няколко основни вида търсене: пълно структурно търсене (търсене по идентичност), субструктурно търсене, търсене по подобие, 3D търсене. Пълното структурно търсене в голяма база данни означава да се намери точно кой запис от базата данни отговаря на търсената структура. За тази задача не е най-ефективно да се използва пълната топологична информация от таблицата на свързаност. Обикновено, пълното структурно търсене е базирано на някое уникално структурно представяне, например „уникален SMILES” или структурни хеш-кодове [10]. Уникалните представяния за всички структури в базата данни са предварително изчислени и съхранени. Процесът на търсене се основава на сравнението между търсения структурен низ (хеш-код) и всяка стойност от базата данни. Този подход е много по-бърз от класическото субструктурно търсене.
Алгоритъмът на субструктурното търсене, прилаган за големи бази данни, има две фази: скрининг (пресяване) и търсене на изоморфизъм (mapping - съпоставяне) [11]. Обикновено, в скрининг етапа повече от 90% от „кандидатите” в базата данни са отхвърлени и след това останалите структури се използват в класически алгоритъм за изоморфизъм. Субструктурното търсене е процес на идентифициране (определяне, откриване) на части от дадената структура, които са еквивалентни на търсената субструктура. Графът GQ е субструктура на GR само и единствено, ако всички атоми от GQ могат да бъдат съпоставени на атоми от GR по такъв начин, че връзките на GQ да се нанесат върху съответстващите връзки, които свързват нанесените атоми от GR. Всяко съпоставяне между GQ и GR, също може да бъде разгледано като функция на типа M: GQ –> GR.
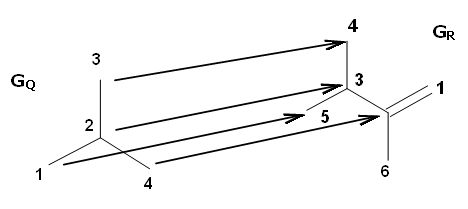
Фигура 3. Съпоставяне между търсената
и референтната структури (1–>5, 2–>3, 3–>4, 4–>2 )
4. Представяне на 2D структури. Това е представяне на структурата на съединението в една равнина, при което се спазват набор от правила за геометрично визуализиране на атомите и връзките. Терминът „2D” в контекста може да бъде малко подвеждащ. Въпреки че се използват, 2D атомните координати, в повечето случаи, не представят съдържателна химична информация. 2D координатите се използват само за структурно изобразяване, като векторни графики (2D структурни диаграми). Терминът „2D” не трябва да се свързва с някаква геометрична информация, а само с топологична такава, защото 2D диаграмата описва много добре топологията на даден граф. 2D представянето е графичният вариант на таблицата на свързаност, като основната цел на 2D представянето е структурата да бъде “красиво” изобразена.
5. Представяне на 3D структури. Пълната геометрична конфигурация на молекулата е описана чрез добавянето на 3D атомни координати към таблицата на свързаност. Координатите могат да бъдат Декартови или вътрешни координати (дължини на връзки, валентни ъгли, диедрични ъгли).
Декартовите координати:
{ (x1, y1, z1), (x2, y2, z2), ... ( xn, yn, zn) }
(имат ефективна употреба при визуализация и 3D структурно подобие, както и при фармакофорни съответствия.
Вътрешните координати:
{ r1, r2, ... rm , q1, q2, ... qs, w1, w2, ... wk }
се употребяват ефективно за изчисляване на основните членове на енергията в молекулната механика и други молекулни свойства.
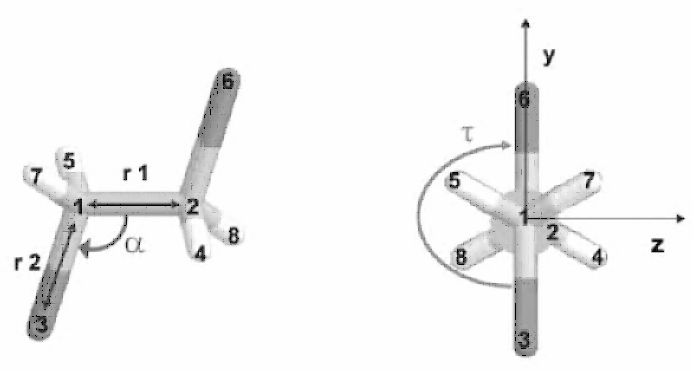
Фигура 4. Елементи от 3D структурата
на 1,2-дихлороетана във вътрешни координати: дължини на връзки r1
и r2, валентен ъгъл a
и диедричен ъгъл t.
Обикновено, в 3D равнината водородните атоми се разглеждат експлицитно [водородните атоми трябва да бъдат изрично описани], докато в 2D равнината могат да бъдат разглеждани имплицитно (по подразбиране, т.е. принадлежащи на други тежки атоми) или експлицитно, като обикновени атоми, заемащи допълнително място в таблицата на свързаност. Различните типове растерни графики играят много важна роля за визуализирането на 3D информацията. Други 3D подходи са молекулните повърхности, които се използват обикновено за представяне на основната молекулна форма и различни молекулни свойства, като функции на 3D пространствените координати. Стеричните и електронните свойства на молекулата зависят от това как нейните атоми могат да бъдат позиционирани в пространството. От тук следва и големият интерес към развитието на алгоритми и системи от база данни, които се занимават с 3D представяния на молекулите и техните конформационно зависими свойства.
[1] J. Gasteiger, T. Engel. Chemoinformatics
a textbook. WILEY-VCH Verlag GmbH & Co, 2003.
[2] D. Massart, B. Vandenginste, S. Deming,
Y. Michotte, L. Kaufman. Chemometrics: a textbook. Elsevier, 1988.
[3] J. Gasteiger, T. Engel, “Chemoinformatics:
a textbook”, Chapter 2, WILEY-VCH Verlag, 2003.
[4] D.Weininger, SMILES, a Chemical Language
for Information Systems. 1. Introduction to Methodology and Encoding Rules;
J. Chem. Inf. Comput. Sci. 1988, 28, 31-36.
[5] http://daylight.com/ daylight site,
SMILES tutorial, Daylight.
[6] S. Ash, M.A. Cline, R.W. Homer, T.
Hurst, and G.B. Smith. SYBYL Line Notation(SLN): A Versatile Language for
Chemical Structure Representation J. Chem. Info.Comp. Sci. 37:71-79 (1997).
[7] J.M. Barnard, C.J. Jochum, S.M. Welford,
ROSDAL: A universal structure/ substructure representation for PC-host
communication, in Chemical Structure Information Systems: Interfaces Communication;
and Standarts, WA. Warr (Ed.), ACS Symposium Series No.400, American Chemical
Society, Washington, DC, 1989, 76-81.
[8] http://daylight.com/ daylight site,
SMARTS tutorial, Daylight
[9] J.M. Barnard, Structure representation
and searching, In Chemical Structure Systems; J. Chem. Inf. Comput. Sci.
1991, 31, 64-68
[10] W. D. Ihlenfeldt, J. Gasteiger, Hash
Codes For The Identification And Classification Of Molecular-Structure
Elements; J. Comput. Chem. 1994, 15, 793-813
[11] J. Gasteiger, T. Engel, “Chemoinformatics:
a textbook”, Chapter 6, WILEY-VCH Verlag, 2003.
..
Автор: Доц.
д-р Николай Кочев
[ това е материал от брой 42 от август 2010 г. на списание "Коснос" www.kosnos.com ]